记一次Quartz重复调度(任务重复执行)的问题排查 |
您所在的位置:网站首页 › quartz 调度线程 › 记一次Quartz重复调度(任务重复执行)的问题排查 |
记一次Quartz重复调度(任务重复执行)的问题排查
|
点击关注公众号,实用技术文章及时了解 公司前期改用quartz做任务调度,一日的调度量均在两百万次以上。随着调度量的增加,突然开始出现job重复调度的情况,且没有规律可循。网上也没有说得较为清楚的解决办法,于是我们开始调试Quartz源码,并最终找到了问题所在。如果没有耐性看完源码解析,可以直接拉到文章最末,有直接简单的解决办法。 注:本文中使用的quartz版本为2.3.0,且使用JDBC模式存储Job。 2. 准备首先,因为本文是代码级别的分析文章,因而需要提前了解Quartz的用途和用法,网上还是有很多不错的文章,可以提前自行了解。 其次,在用法之外,我们还需要了解一些Quartz框架的基础概念: Quartz把触发job,叫做fire。TRIGGER_STATE是当前trigger的状态,PREV_FIRE_TIME是上一次触发时间,NEXT_FIRE_TIME是下一次触发时间,misfire是指这个job在某一时刻要触发,却因为某些原因没有触发的情况。 Quartz在运行时,会起两类线程(不止两类),一类用于调度job的调度线程(单线程),一类是用于执行job具体业务的工作池。 Quartz自带的表里面,本文主要涉及以下3张表: triggers表。triggers表里记录了,某个trigger的PREV_FIRE_TIME(上次触发时间),NEXT_FIRE_TIME(下一次触发时间),TRIGGER_STATE(当前状态)。虽未尽述,但是本文用到的只有这些。 locks表。Quartz支持分布式,也就是会存在多个线程同时抢占相同资源的情况,而Quartz正是依赖这张表,处理这种状况,至于如何做到,参见3.1。 fired_triggers表,记录正在触发的triggers信息。 TRIGGER_STATE,也就是trigger的状态,主要有以下几类: 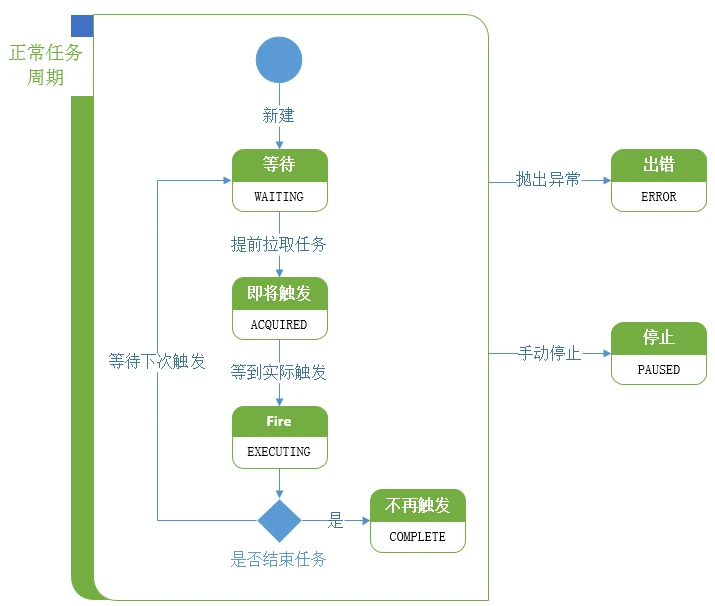 图2-1 trigger状态变化图
图2-1 trigger状态变化图
trigger的初始状态是WAITING,处于WAITING状态的trigger等待被触发。调度线程会不停地扫triggers表,根据NEXT_FIRE_TIME提前拉取即将触发的trigger,如果这个trigger被该调度线程拉取到,它的状态就会变为ACQUIRED。因为是提前拉取trigger,并未到达trigger真正的触发时刻,所以调度线程会等到真正触发的时刻,再将trigger状态由ACQUIRED改为EXECUTING。如果这个trigger不再执行,就将状态改为COMPLETE,否则为WAITING,开始新的周期。如果这个周期中的任何环节抛出异常,trigger的状态会变成ERROR。如果手动暂停这个trigger,状态会变成PAUSED。 3. 开始排查 3.1分布式状态下的数据访问前文提到,trigger的状态储存在数据库,Quartz支持分布式,所以如果起了多个quartz服务,会有多个调度线程来抢夺触发同一个trigger。mysql在默认情况下执行select 语句,是不上锁的,那么如果同时有1个以上的调度线程抢到同一个trigger,是否会导致这个trigger重复调度呢?我们来看看,Quartz是如何解决这个问题的。 首先,我们先来看下JobStoreSupport类的executeInNonManagedTXLock()方法:  图3-1 executeInNonManagedTXLock方法的具体实现
图3-1 executeInNonManagedTXLock方法的具体实现
这个方法的官方介绍: /** *Execute the given callback having acquired the given lock. *Depending on the JobStore,the surrounding transaction maybe *assumed to be already present(managed). * *@param lockName The name of the lock to acquire,for example *"TRIGGER_ACCESS".If null, then no lock is acquired ,but the *lockCallback is still executed in a transaction. */也就是说,传入的callback方法在执行的过程中是携带了指定的锁,并开启了事务,注释也提到,lockName就是指定的锁的名字,如果lockName是空的,那么callback方法的执行不在锁的保护下,但依然在事务中。 这意味着,我们使用这个方法,不仅可以保证事务,还可以选择保证,callback方法的线程安全。 接下来,我们来看一下executeInNonManagedTXLock(…)中的obtainLock(conn,lockName)方法,即抢锁的过程。这个方法是在Semaphore接口中定义的,Semaphore接口通过锁住线程或者资源,来保护资源不被其他线程修改,由于我们的调度信息是存在数据库的,所以现在查看DBSemaphore.java中obtainLock方法的具体实现: 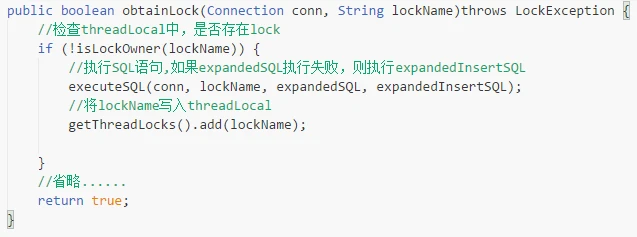 图3-2 obtainLock方法具体实现
图3-2 obtainLock方法具体实现
我们通过调试查看expandedSQL和expandedInsertSQL这两个变量:  图3-3 expandedSQL和expandedInsertSQL的具体内容
图3-3 expandedSQL和expandedInsertSQL的具体内容
图3-3可以看出,obtainLock方法通过locks表的一个行锁(lockName确定)来保证callback方法的事务和线程安全。拿到锁后,obtainLock方法将lockName写入threadlocal。当然在releaseLock的时候,会将lockName从threadlocal中删除。 总而言之,executeInNonManagedTXLock()方法,保证了在分布式的情况,同一时刻,只有一个线程可以执行这个方法。 3.2 quartz的调度过程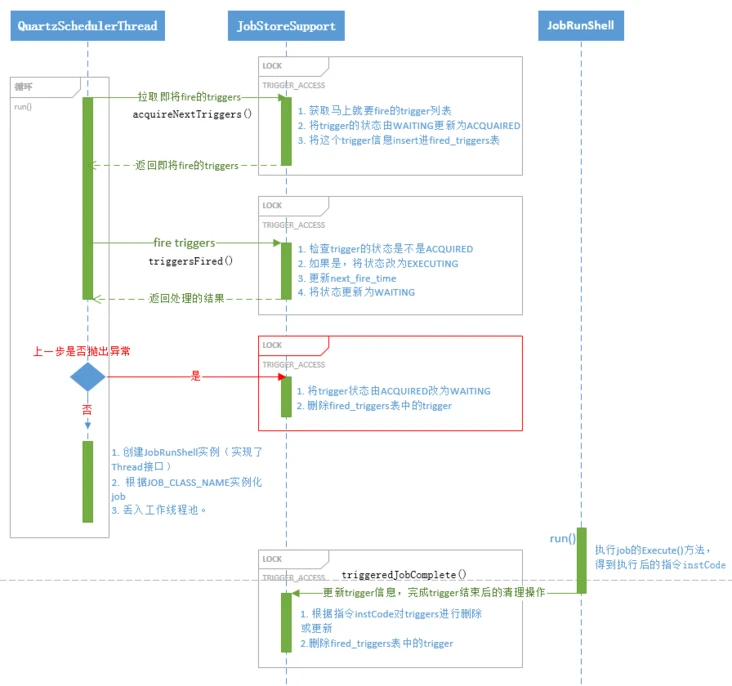 图3-4 Quartz的调度时序图
图3-4 Quartz的调度时序图
QuartzSchedulerThread是调度线程的具体实现,图3-4 是这个线程run()方法的主要内容,图中只提到了正常的情况下,也就是流程中没有出现异常的情况下的处理过程。由图可以看出,调度流程主要分为以下三步: 1)拉取待触发trigger:调度线程会一次性拉取距离现在,一定时间窗口内的,一定数量内的,即将触发的trigger信息。那么,时间窗口和数量信息如何确定呢,我们先来看一下,以下几个参数: idleWaitTime:默认30s,可通过配置属性org.quartz.scheduler.idleWaitTime设置。 availThreadCount:获取可用(空闲)的工作线程数量,总会大于1,因为该方法会一直阻塞,直到有工作线程空闲下来。 maxBatchSize:一次拉取trigger的最大数量,默认是1,可通过org.quartz.scheduler.batchTriggerAcquisitionMaxCount改写 batchTimeWindow:时间窗口调节参数,默认是0,可通过org.quartz.scheduler.batchTriggerAcquisitionFireAheadTimeWindow改写 misfireThreshold:超过这个时间还未触发的trigger,被认为发生了misfire,默认60s,可通过org.quartz.jobStore.misfireThreshold设置。 调度线程一次会拉取NEXT_FIRE_TIME小于(now + idleWaitTime +batchTimeWindow),大于(now - misfireThreshold)的,min(availThreadCount,maxBatchSize)个triggers,默认情况下,会拉取未来30s,过去60s之间还未fire的1个trigger。随后将这些triggers的状态由WAITING改为ACQUIRED,并插入fired_triggers表。 2)触发trigger:首先,我们会检查每个trigger的状态是不是ACQUIRED,如果是,则将状态改为EXECUTING,然后更新trigger的NEXT_FIRE_TIME,如果这个trigger的NEXT_FIRE_TIME为空,也就是未来不再触发,就将其状态改为COMPLETE。如果trigger不允许并发执行(即Job的实现类标注了@DisallowConcurrentExecution),则将状态变为BLOCKED,否则就将状态改为WAITING。 3)包装trigger,丢给工作线程池:遍历triggers,如果其中某个trigger在第二步出错,即返回值里面有exception或者为null,就会做一些triggers表,fired_triggers表的内容修正,跳过这个trigger,继续检查下一个。否则,则根据trigger信息实例化JobRunShell(实现了Thread接口),同时依据JOB_CLASS_NAME实例化Job,随后我们将JobRunShell实例丢入工作线。 在JobRunShell的run()方法,Quartz会在执行job.execute()的前后通知之前绑定的监听器,如果job.execute()执行的过程中有异常抛出,则执行结果jobExEx会保存异常信息,反之如果没有异常抛出,则jobExEx为null。然后根据jobExEx的不同,得到不同的执行指令instCode。 JobRunShell将trigger信息,job信息和执行指令传给triggeredJobComplete()方法来完成最后的数据表更新操作。例如如果job执行过程有异常抛出,就将这个trigger状态变为ERROR,如果是BLOCKED状态,就将其变为WAITING等等,最后从fired_triggers表中删除这个已经执行完成的trigger。注意,这些是在工作线程池异步完成。 3.3 排查问题在前文,我们可以看到,Quartz的调度过程中有3次(可选的)上锁行为,为什么称为可选?因为这三个步骤虽然在executeInNonManagedTXLock方法的保护下,但executeInNonManagedTXLock方法可以通过设置传入参数lockName为空,取消上锁。在翻阅代码时,我们看到第一步拉取待触发的trigger时: public List acquireNextTriggers(final long noLaterThan, final int maxCount, final long timeWindow)throws JobPersistenceException { String lockName; //判断是否需要上锁 if (isAcquireTriggersWithinLock() || maxCount > 1) { lockName = LOCK_TRIGGER_ACCESS; } else { lockName = null; } return executeInNonManagedTXLock(lockName, new TransactionCallback(){ public List execute(Connection conn) throws JobPersistenceException { return acquireNextTrigger(conn, noLaterThan, maxCount, timeWindow); } }, new TransactionValidator() { //省略 }); }在加锁之前对lockName做了一次判断,而非像其他加锁方法一样,默认传入的就是LOCK_TRIGGER_ACCESS: public List triggersFired(final List triggers) throws JobPersistenceException { //默认上锁 return executeInNonManagedTXLock(LOCK_TRIGGER_ACCESS, new TransactionCallback() { //省略 },new TransactionValidator() { //省略 }); }通过调试发现isAcquireTriggersWithinLock()的值是false,因而导致传入的lockName是null。我在代码中加入日志,可以更清楚的看到这个过程。  图3-5 调度日志
图3-5 调度日志
由图3-5可以清楚看到,在拉取待触发的trigger时,默认是不上锁。如果这种默认配置有问题,岂不是会频繁发生重复调度的问题?而事实上并没有,原因在于Quartz默认采取乐观锁,也就是允许多个线程同时拉取同一个trigger。我们看一下Quartz在调度流程的第二步fire trigger的时候做了什么,注意此时是上锁状态: protected TriggerFiredBundle triggerFired(Connection conn, OperableTrigger trigger) throws JobPersistenceException { JobDetail job; Calendar cal = null; // Make sure trigger wasn't deleted, paused, or completed... try { // if trigger was deleted, state will be STATE_DELETED String state = getDelegate().selectTriggerState(conn,trigger.getKey()); if (!state.equals(STATE_ACQUIRED)) { return null; } } catch (SQLException e) { throw new JobPersistenceException("Couldn't select trigger state: " + e.getMessage(), e); }调度线程如果发现当前trigger的状态不是ACQUIRED,也就是说,这个trigger被其他线程fire了,就会返回null。在3.2,我们提到,在调度流程的第三步,如果发现某个trigger第二步的返回值是null,就会跳过第三步,取消fire。在通常的情况下,乐观锁能保证不发生重复调度,但是难免发生ABA问题,我们看一下这是发生重复调度时的日志: 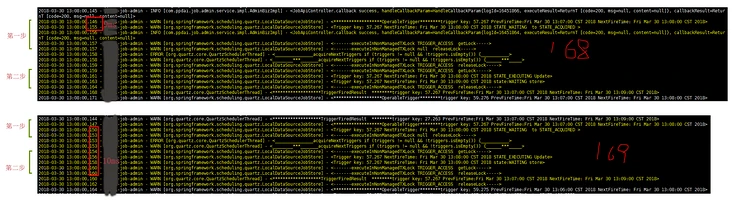 图3-5 重复调度的日志
图3-5 重复调度的日志
在第一步时,也就是quartz在拉取到符合条件的triggers 到将他们的状态由WAITING改为ACQUIRED之间停顿了有超过9ms的时间,而另一台服务器正是趁着这9ms的空档完成了WAITING-->ACQUIRED-->EXECUTING-->WAITING(也就是一个完整的状态变化周期)的全部过程,图示参见图3-6。 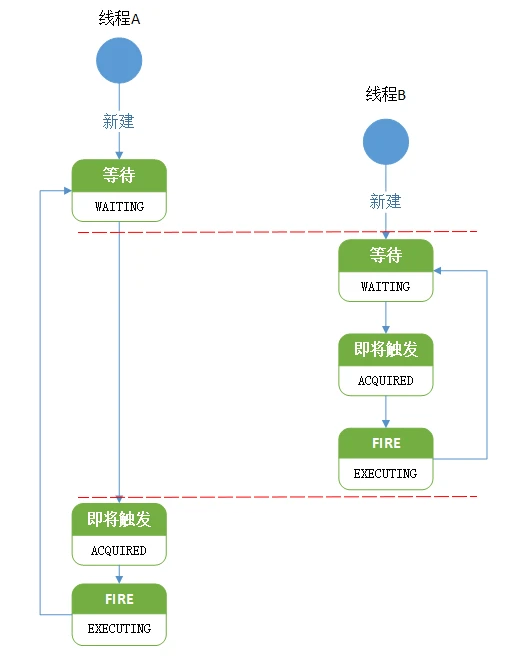 图3-6 重复调度原因示意图
3.4 解决办法
图3-6 重复调度原因示意图
3.4 解决办法
如何去解决这个问题呢?在配置文件加上org.quartz.jobStore.acquireTriggersWithinLock=true,这样,在调度流程的第一步,也就是拉取待即将触发的triggers时,是上锁的状态,即不会同时存在多个线程拉取到相同的trigger的情况,也就避免的重复调度的危险。 推荐: 主流Java进阶技术(学习资料分享)
PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧! |

【本文地址】
今日新闻 |
推荐新闻 |